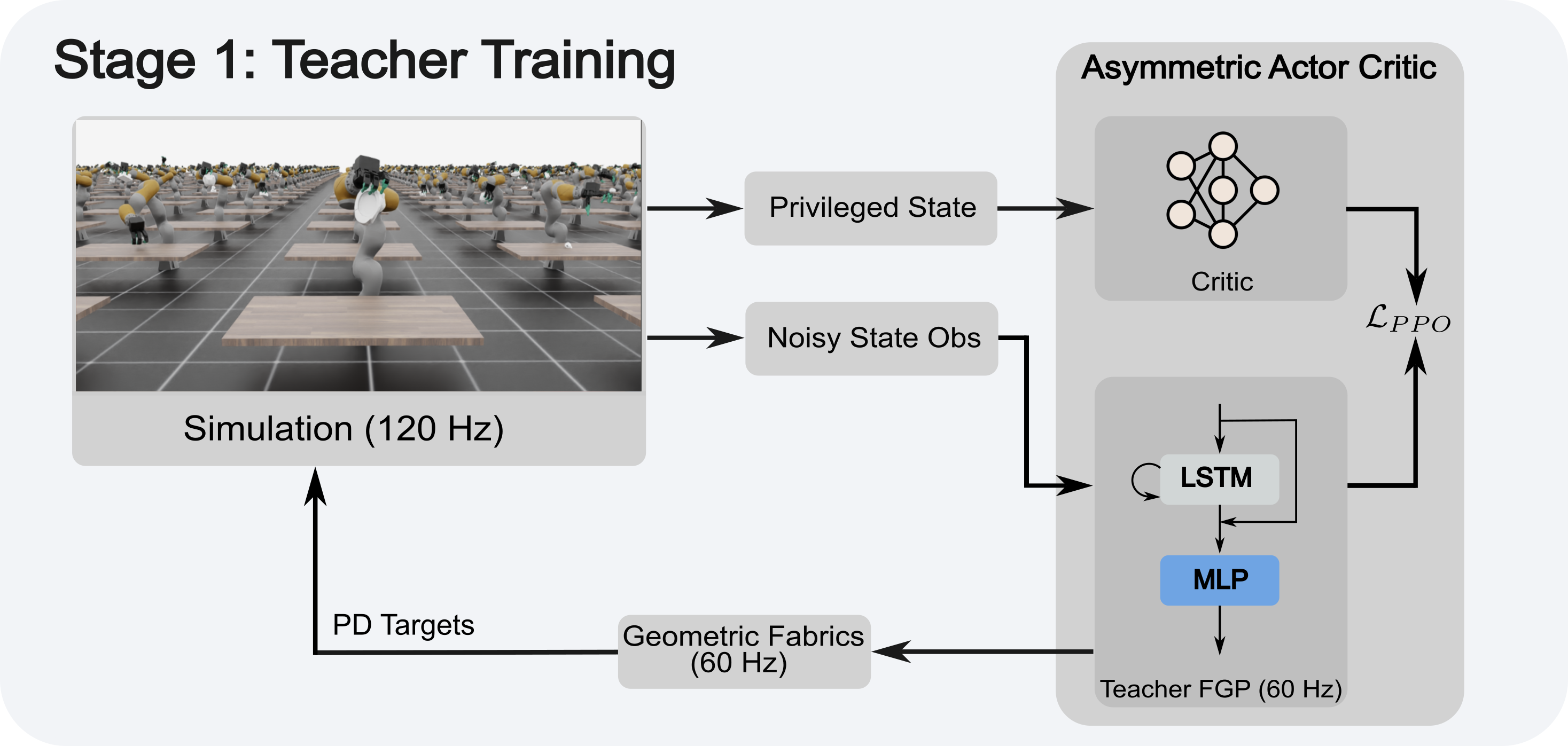
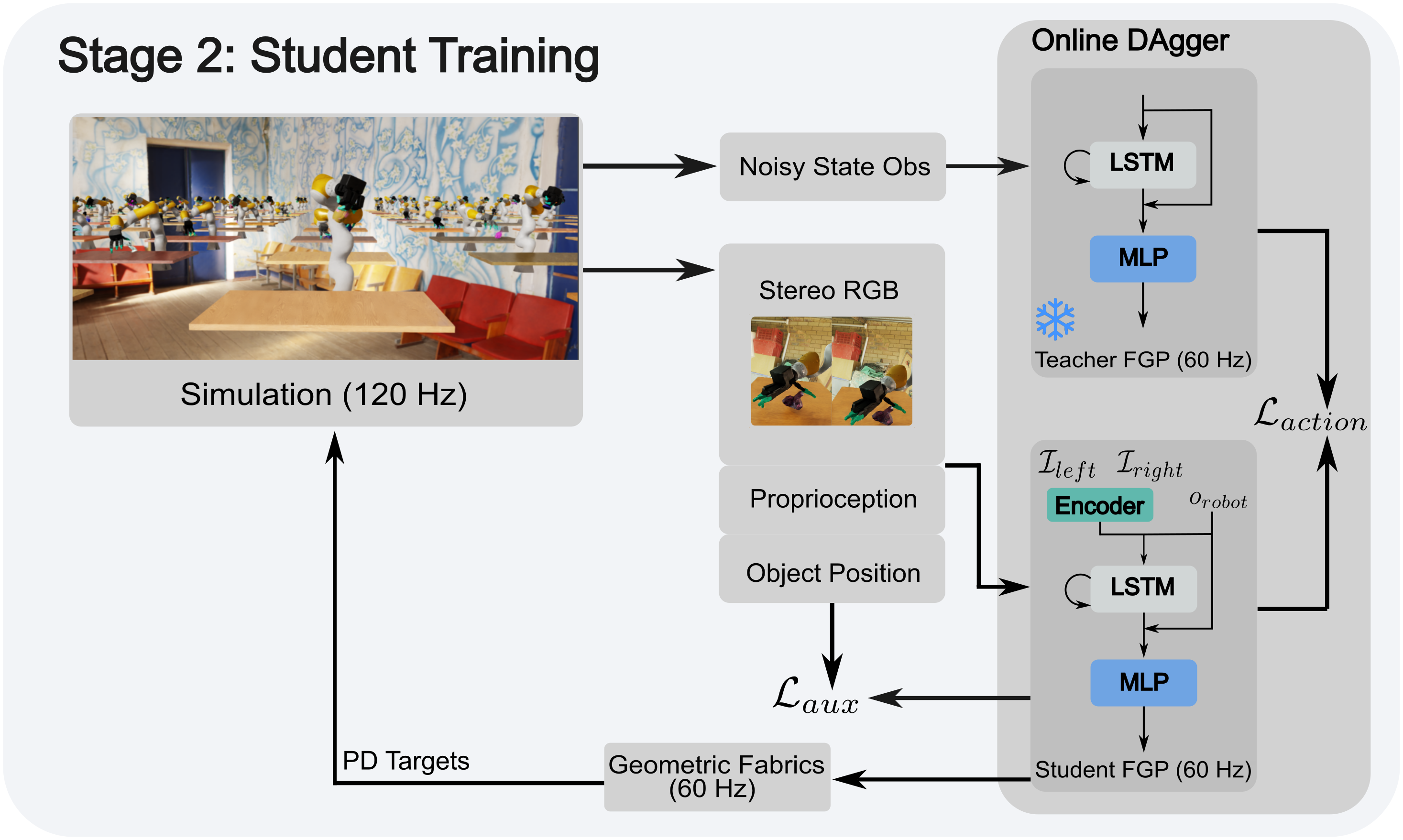
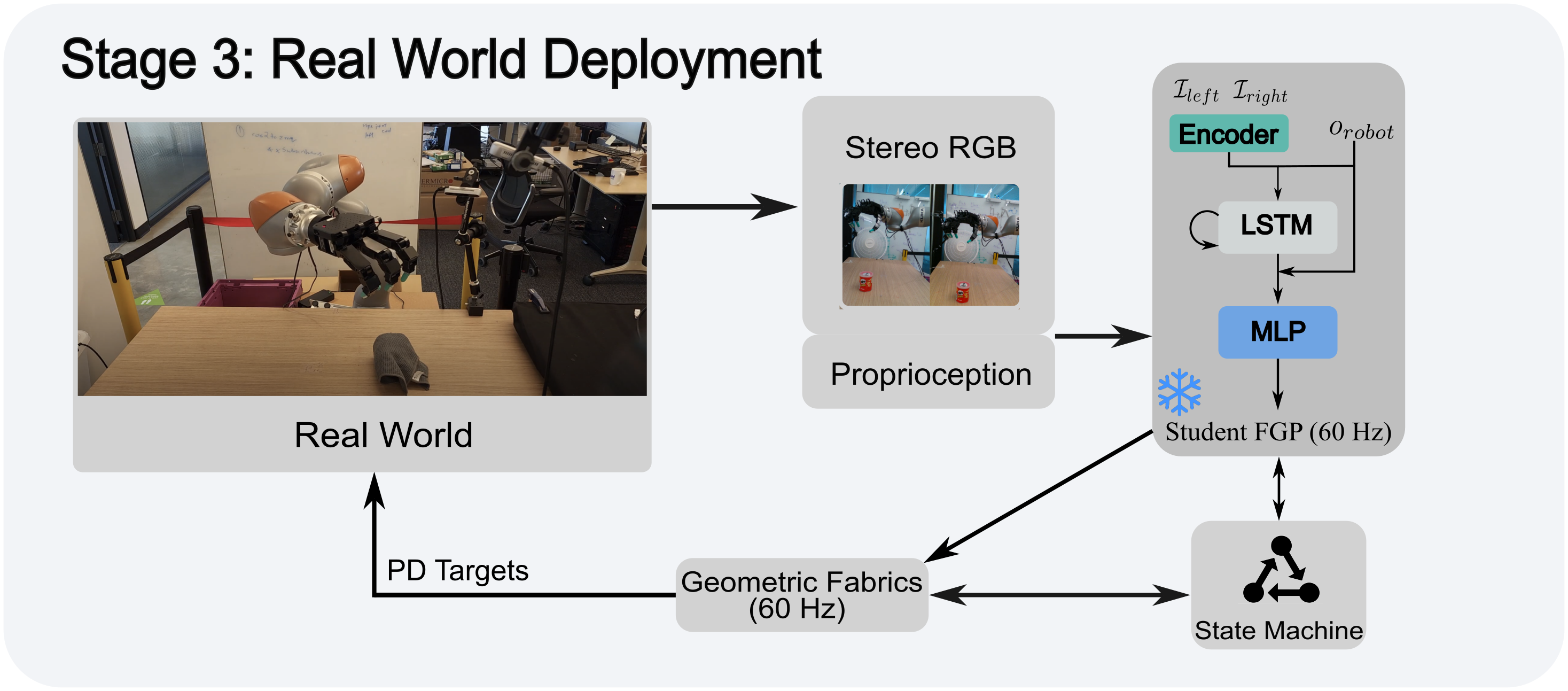
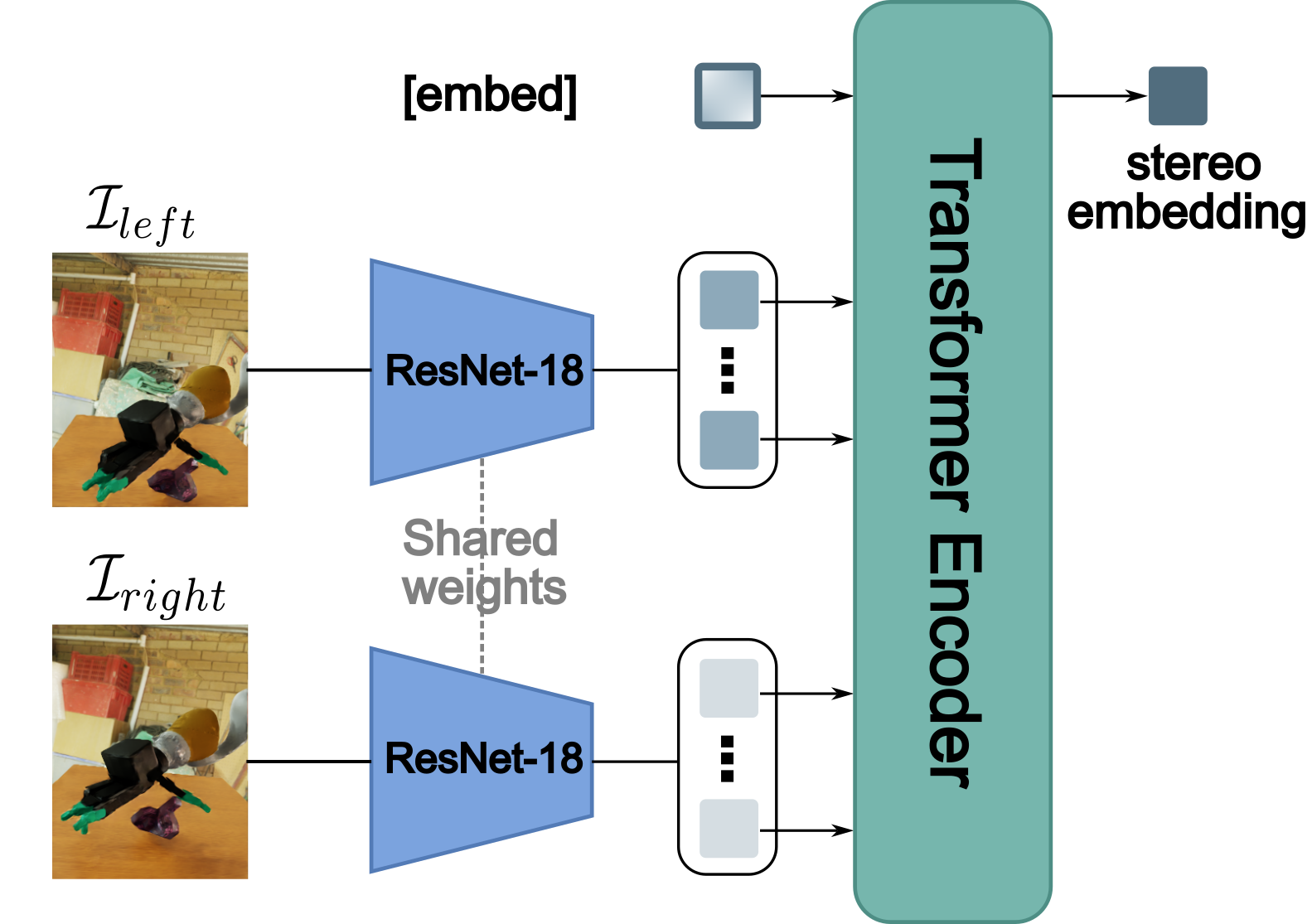
One of the most important yet challenging skills for robots is dexterous multi-fingered grasping of a diverse range of objects. Much of the prior work is limited by the speed, dexterity, or reliance on depth maps. In this paper, we introduce DextrAH-RGB, a system that can perform dexterous arm-hand grasping end2end from stereo RGB input. We train a teacher policy in simulation through reinforcement learning that acts on a geometric fabric action space to ensure reactivity and safety. We then distill this teacher into an RGB-based student in simulation. To our knowledge, this is the first work that is able to demonstrate robust sim2real transfer of an end2end RGB-based policy for a complex, dynamic, contact-rich tasks such as dexterous grasping. Our policies are also able to generalize to grasping novel objects with unseen geometry, texture, or lighting conditions during training.